1.3 เริ่มต้นใช้งาน - Git ขั้นพื้นฐาน
Git ขั้นพื้นฐาน
แล้วสรุปสั้น ๆ ได้ว่า Git คืออะไรล่ะ? ส่วนนี้เป็นส่วนสำคัญที่คุณต้องพยายามทำความเข้าใจเพราะถ้าคุณเข้าใจว่า Git คืออะไรและทำงานอย่างไร คุณจะสามารถใช้งาน Git ได้อย่างมีประสิทธิภาพและง่ายดายมาก เวลาคุณเรียนรู้ Git ให้พยายามลืมสิ่งต่าง ๆ ที่คุณอาจจะรู้อยู่แล้วจาก VCS อื่น ๆ เช่น Subversion หรือ Perforce เพราะคุณอาจสับสนคอนเซ็ปต์จากเครื่องมือเหล่านั้นได้ เหตุผลก็เพราะ Git เก็บและมองข้อมูล่างจากระบบอื่น ๆ เป็นอย่างมากถึงแม้ว่าจะทำงานคล้ายกันก็ตาม
เก็บ Snapshot แทนผลต่าง
ความแตกต่างมากที่สุดระหว่าง Git และ VCS อื่น ๆ (เช่น Subversion และผองเพื่อน) คือ วิธีที่ Git มองข้อมูลต่าง ๆ โดยทั่วไประบบอื่นมักจะเก็บข้อมูลในรูปแบบของการแก้ไขที่เกิดขึ้นกับไฟล์ต่าง ๆ ระบบเหล่านี้ (เช่น CVS, Subversion, Perforce, Bazaar, ฯลฯ) จะมองข้อมูลในรูปแบบของไฟล์และการแก้ไขต่าง ๆ ที่เกิดขึ้นกับไฟล์แต่ละไฟล์ ดังเช่นในรูปที่ 1-4
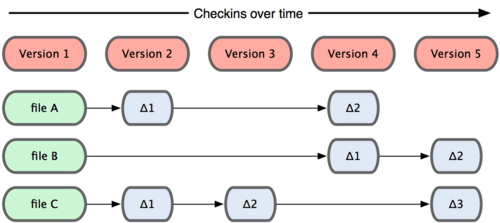
รูปที่ 1-4. ระบบอื่น ๆ มักจะเก็บข้อมูลโดยอิงกับการแก้ไขที่เกิดขึ้นกับไฟล์
Git ไม่ได้มองและจัดเก็บข้อมูลในลักษณะนี้ แต่จะคิดว่าข้อมูลของมันเป็นเสมือนภาพถ่าย(snapshot)ของระบบไฟล์ขนาดเล็กๆ ทุกครั้งที่มีการ commit หรือบันทึกสถานะของโปรเจคลงใน Git มันจะทำการถ่ายภาพของไฟล์ทั้งหมดในตอนนั้นและบันทึกการอ้างอิงไปยัง snapshot นั้น เพื่อให้การจัดเก็บนั้นมีประสิทธิภาพ ถ้าไฟล์ใดที่ไม่ได้มีการเปลี่ยนแปลง Git ก็จะไม่บันทึกไฟล์นั้นอีกครั้ง เพียงแต่จะทำการเชื่อมโยงไปยังไฟล์เดิมที่เคยถูกบันทึกเอาไว้อยู่แล้ว Git จะมองข้อมูลดังรูปที่ 1-5
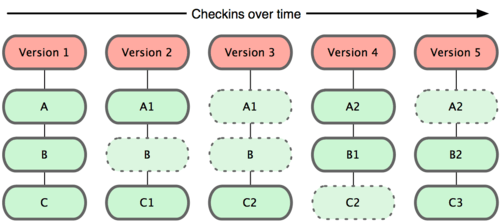
รูปที่ 1-5. Git เก็บข้อมูลเป็น snapshot ของโปรเจค
นี่คือความแตกต่างที่สำคัญระหว่าง Git กับ VCSs ตัวอื่นๆ มันทำให้ Git ทำได้เกือบทุกด้านของระบบ VCS อื่นๆ ซึ่งส่วนใหญ่ก็คัดลอกมาจากรุ่นก่อนๆ นี่ทำให้ Git เป็นเหมือนกับระบบไฟล์ขนาดเล็กที่มีเครื่องมือ(tools)อันทรงพลังอย่างน่าเหลือเชื่อครอบอยู่ แทนที่จะเป็น VCS แบบทั่วไป เราจะมาสำรวจข้อดีที่คุณจะได้รับจากแนวคิดแบบนี้เมื่อเรากล่าวถึงเรื่อง การแตกสาขา(Git branching) ในบทที่ 3
การทำงานเกือบทุกอย่างเป็นการทำงานในเครื่องตัวเอง
การทำงานโดยส่วนใหญ่ของ Git จะใช้ไฟล์และทรัพยากรในเครื่องของเราเท่านั้น ปกติจะไม่มีข้อมูลใดๆ ที่จำเป็นต้องใช้จากคอมพิวเตอร์เครื่องอื่นๆ ในเน็ตเวิร์ก แต่หากคุณเคยใช้ CVCS อื่นที่การทำงานส่วนใหญ่ต้องใช้ข้อมูลบนเน็ตเวิร์กจำนวนมาก ในแง่นี้ก็จะทำให้คุณรู้สึกมีความสุขกับความเร็วในการทำงานของ Git เพราะว่าคุณจะมีประวัติการเปลี่ยนแปลงทั้งหมดของโปรเจคอยู่ในเครื่องของคุณอยู่แล้วและพร้อมที่จะทำงานได้ทันที
ตัวอย่างเช่น ถ้าจะดูประวัติย้อนหลังของโปรเจค Git ไม่จำเป็นที่จะต้องไปดึงข้อมูลจากเซิร์ฟเวอร์แล้วจึงแสดงผลให้คุณได้ มันแค่อ่านโดยตรงจากฐานข้อมูลในเครื่องของคุณ หมายความว่าคุณสามารที่จะดูประวัติของโปรเจคได้ทันที หากคุณจะดูความเปลี่ยนแปลงของไฟล์ในรุ่นปัจจุบันกับเมื่อหนึ่งเดือนที่แล้ว Git ก็สามารถค้นหาไฟล์เมื่อเดือนก่อนในเครื่องของเราแล้วทำการคำนวณความแตกต่าง แทนที่จะถามเครื่องเซิร์ฟเวอร์ให้ดึงไฟล์เก่ามาให้
ซึ่งก็มีโอกาสน้อยมากที่คุณไม่สามารถทำงานได้ถ้าหากออฟไลน์อยู่ หากคุณต้องเดินทางอยู่บนเครื่องหรือบนรถไฟและอยากจะทำงานสักหน่อย คุณก็สามารถ commit ได้อย่างมีความสุขจนกว่าจะเชื่อมต่อเน็ตเวิร์กได้แล้วอัพโหลด หากที่บ้านของคุณมีปัญหาเรื่องเน็ตเวิร์กคุณก็ยังคงทำงานได้ ถ้าเป็นระบบอื่นทำแบบนี้ไม่ได้แน่ และจะทำอะไรแทบจะไม่ได้เลยหากคุณเชื่อมต่อไปยังเซิร์ฟเวอร์ไม่ได้ ยิ่งในโปรแกรม Subversion และ CVS คุณสามารถแก้ไขไฟล์ต่างๆ ได้แต่จะไม่สามารถ commit ได้เพราะฐานข้อมูลมันออฟไล์อยู่ นี่อาจจะไม่ใช้เรื่องใหญ่อะไรแต่ก็ได้แต่คุณจะแปลกใจในความสามารถนี้ที่ Git ทำได้
Git มีความเที่ยงตรง
ทุกอย่างที่ Git ทำการบันทึกเอาไว้จะถูกทำการ Checksum แล้วนำมาใช้เป็นตัวอ้างอิง นั่นทำให้ไม่มีทางที่เราจะแก้ไขข้อมูลของไฟล์และไดเร็กทอรี่ใดโดยที่ Git จะไม่รู้ ซึ่งฟังก์ชันนี้จะอยู่ในระดับล่างและเป็นหลักการของ Git คุณจะไม่มีทางที่จะทำข้อมูลสูญหายระหว่างการโยกย้ายหรือรับไฟล์ที่เสียหายโดย Git จะสามารถตรวจพบได้
กลไกที่ Git ใช้ในการทำ Checksum คือการแฮช(hash)แบบ SHA-1 ซึ่งผลลัพธ์จะได้ออกมาเป็นตัวอักษร 40 ตัวที่แทนเลขฐานสิบหก(0-9 และ a-f)จากการคำนวณเนื้อหาในไฟล์หรือโครงสร้างของไดเร็กทอรี่ของ Git ซึ่ง SHA-1 มีลักษณะดังนี้
24b9da6552252987aa493b52f8696cd6d3b00373
คุณจะเห็นว่าผลของการแฮช(hash)เหล่านี้อยู่ในทุกที่ใน Git เพราะจะถูกใช้บ่อยครั้ง ซึ่งจริงๆแล้ว Git ไม่ได้เก็บบันทึกข้อมูลทุกอย่างตามชื่อไฟล์แต่เก็บในฐานข้อมูลของ Git แล้วสามารถอ้างถึงด้วยค่าแฮช(hash)ของข้อมูลของไฟล์
Git เพียงแต่เพิ่มข้อมูล
เมื่อคุณกระทำอะไรสักอย่างใน Git เนื้อหาเกือบทั้งหมดนั้นก็จะถูกเพิ่มเข้าไปในฐานข้อมูลของ Git เท่านั้น มันเป็นเรื่องยากมากๆ ที่เราจะใช้ระบบที่ทำอะไรลงไปแล้วไม่สามารถย้อนคืนกลับมาได้หรือลบแล้วลบเลย เช่นเดียวกันกับ VCS ตัวอื่นๆ คุณสามารถสูญเสียข้อมูลหรือแก้ไขผิดพลาดได้โดยที่ยังไม่ทันได้ commit แต่ถ้าคุณ commit ลงใน snapshot ของ Git แล้วมันก็ยากที่จะสูญหายได้โดยเฉพาะอย่างยิ่งถ้าคุณทำการผลัก(push)ฐานข้อมูลของคุณไปไว้ที่อื่นๆ
สิ่งนี้ทำให้การใช้ Git ได้อย่างมีความสุข เพราะเรารู้ว่าเราสามารถทำการทดลองได้โดยที่ไม่มีอันตรายร้ายแรง เราจะดูเนื้อหาลึกๆว่า Git จัดเก็บข้อมูลอย่างไร และเราสามารถกู้ข้อมูลที่สูญหายไปได้อย่างไร ในบทที่ 9
สามสถานะ
ทีนี้เราต้องให้ความสนใจหน่อย เพราะนี่คือสิ่งสำคัญของ Git ที่จะต้องจำให้ได้ ถ้าคุณต้องการจะศึกษาส่วนอื่นๆต่อไปของ Git อย่างราบรื่น ไฟล์ของคุณใน Git จะมีอยู่ 3 สถานะ คือ ยืนยันแล้ว(committed), ถูกแก้ไข(modified) และ อยู่ในขั้นตอน(staged) ซึ่ง Committed หมายถึงข้อมูลที่ถูกบันทึกเรียบร้อยแล้วในฐานข้อมูลในเครื่องของคุณ Modified หมายถึงไฟล์ของคุณได้ถูกแก้ไขแล้วแต่ยังไม่ได้ยืนยัน(commit)ลงในฐานข้อมูลของคุณ Staged หมายถึงคุณได้ทำเครื่องหมายไว้ที่ไฟล์ที่ถูกแก้ไขในเวอร์ชันปัจจุบันเพื่อที่จะรอการ commit ใน snapshot ถัดไป
นี่ทำให้โปรเจคที่ใช้ Git มี 3 ส่วน คือ the Git directory, working directory, และ staging area.
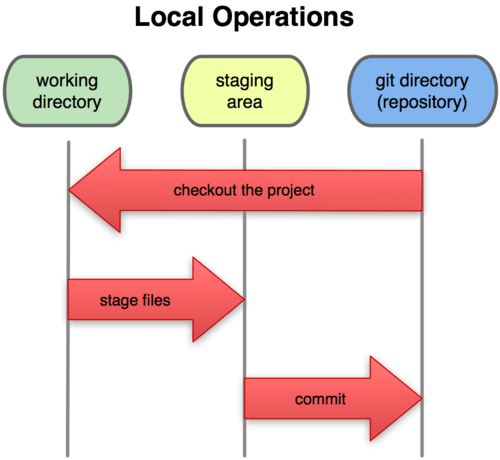
Figure 1-6. Working directory, staging area, และ git directory.
Git directory เป็นที่ที่ Git ใช้เก็บ metadata และออปเจ็คของฐานข้อมูลของโปรเจคของคุณ นี่คือส่วนสำคัญที่สุดของ Git และเป็นส่วนที่จะถูกคัดลอกมาเมื่อคุณทำการโคลน(clone)คลังข้อมูลจากคอมพิวเตอร์เครื่องอื่น
working directory เป็นเวอร์ชันนึงของไฟล์ในโปรเจคที่ถูกดึงออกมาจากฐานข้อมูลที่ถูกบีบอัดไว้ใน Git directory แล้วเก็บไว้ในดิสก์เพื่อให้คุณนำไปใช้หรือเอามาแก้ไข
staging area เป็นไฟล์ธรรมดาไฟล์นึง โดยทั่วไปก็อยู่ใน Git directory ของคุณ ซึ่งเก็บข้อมูลส่วนที่คุณจะทำการ commit ในครั้งถัดไป บางครั้งก็เรียกว่าดัชนี(index) แต่ปกติก็จะเรียกว่า staging area
กระบวนการขั้นตอนพื้นฐานของ Git มีลักษณะดังนี้
- คุณทำการแก้ไขไฟล์ใน working directory ของคุณ
- แล้วทำการ stage ไฟล์เหล่านั้นเพื่อให้มีการใส่ snapshot ลงไปใน staging area ของคุณ
- ทำการยืนยัน(commit)ซึ่งนำไฟล์ที่อยู่ใน staging area ไปเก็บอย่างถาวรใน Git directory
เมื่อไฟล์อยู่ใน Git directory มันจะถือว่าเป็นสถานะ committed ถ้าไฟล์ถูกแก้ไขแล้วถูกเพิ่มลงใน staging area สถานะจะเป็น staged และถ้าไฟล์ถูกแก้ไขแล้วหลังถูกดึงออกมาแต่ไม่ได้เป็นสถานะ staged ก็จะเป็นสถานะ modified ในบทที่ 2 คุณจะได้เรียนรู้เกี่ยวกับสถานะมากกว่านี้และวิธีการที่คุณสามารถใช้ประโยชน์จากสถานะเหล่านี้หรือการข้ามสถานะ staged ได้อย่างไร


ไม่มีความคิดเห็น:
แสดงความคิดเห็น